SPSS数据分组功能介绍
SPSS作为一款专业的数据分析工具,不仅具备强大的统计分析能力,还支持灵活的数据处理功能,其中就包括便捷的“数据分组”操作。许多用户在面对大量连续变量时,常常会困惑如何进行有效分组,本文将为大家带来一份详尽的操作指南,帮助你快速掌握SPSS中的数据分组方法。
了解组距分组的基本原理
当变量值较多且分布范围较广时,通常采用组距分组的方式对数据进行分类整理。该方法的核心在于合理确定分组数目和组距大小。
确定合理的分组数量
分组数量应根据数据特征及样本个数综合判断,一般以能够清晰展现数据分布规律为原则。若分组过少,会导致信息集中、失去细节;而分组过多,则会使数据过于离散,难以形成有效结论。通常可参考Sturges公式来科学设定组数。
计算并设置合适的组距
组距指的是每一组的最大值与最小值之间的差值,其计算方式是将全距(最大值减去最小值)除以所确定的组数。这一数值决定了每组之间的间隔大小,确保分组均匀且具有代表性。
实际操作演示:将数据分为四组
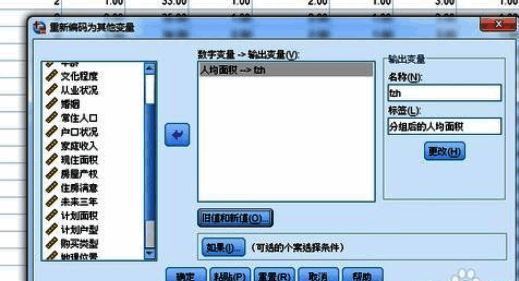
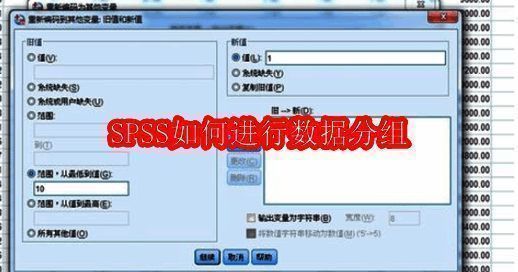
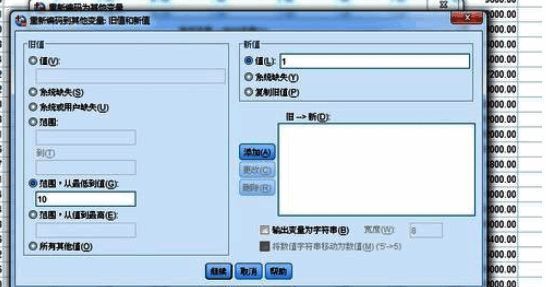
接下来我们通过一个具体的案例来演示如何在SPSS中完成数据分组操作。首先调出相关功能界面,并选择“旧值和新值”的转换方式。
设置分组规则与新变量命名
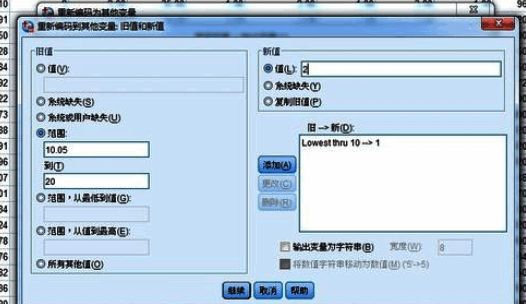
在弹出的对话框中,我们可以将原始变量按照指定区间划分为新的类别。例如,将小于等于10的数值归为第一组,标签设为“1”,设置完成后记得点击“添加”按钮确认规则生效。
定义输出变量名称与标签
在“输出变量”区域,我们需要为新生成的分组变量命名,包括“名称”和“标签”两个字段,以便后续分析时能清楚识别该变量含义。
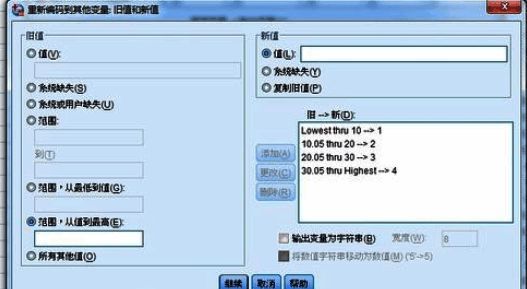
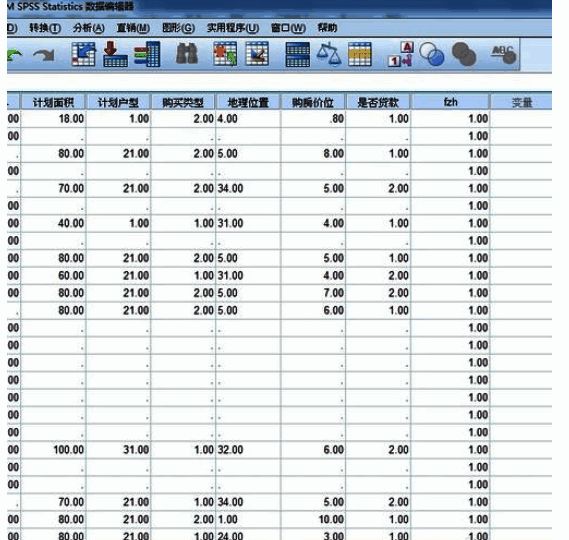
查看最终分组结果
完成所有设置后,系统将自动生成新的分组变量。例如,我们命名为“fzh”的变量即为本次分组的结果,从下图可以看到第一组的具体数据分布情况。